
Artificial Intelligence is now beyond early experimentation. It’s embedded in product ecosystems, customer service workflows, cybersecurity operations, forecasting models, and internal automation initiatives. Yet despite rapid adoption, many organizations still struggle to translate AI ambitions into real, production-ready solutions.
According to industry research, the majority of AI projects stall due to unclear objectives, insufficient data readiness, fragmented infrastructure, and lack of cross-functional coordination. These challenges are not technical problems alone, they are structural and operational. And they are the exact gaps an AI implementation roadmap is designed to prevent.
This article breaks down a practical, six-phase AI integration roadmap. It also provides access to a free Excel-based template that helps technology leaders plan, track, and execute AI projects with clarity and measurable accountability.
What is an AI implementation roadmap?
An AI implementation roadmap is a structured framework that guides an organization through the process of preparing, developing, deploying, and scaling AI solutions. Unlike lightweight strategy decks or isolated use-case lists, a roadmap:
- defines phases, deliverables, dependencies, and required expertise,
- assigns ownership and workload across roles,
- establishes KPIs and performance review cycles,
- exposes risks, constraints, and required process changes,
- links technical activities to strategic business outcomes.
In essence, it acts as a project management backbone for AI adoption, especially in organizations that lack mature MLOps practices or are navigating AI for the first time.
Why AI projects need a roadmap
Implementing AI requires coordinated planning across data, infrastructure, and operations. A roadmap ensures that every technical decision is deliberate, measurable, and aligned with long-term business objectives rather than short-term experimentation.
Across modern AI transformation programs, several consistent engineering realities shape whether an initiative succeeds:
- AI success depends heavily on data quality, not only model selection.
Even the strongest models underperform when data is incomplete, inconsistent, or siloed, making data profiling, cleaning, and integration a non-negotiable first phase. - Cross-functional alignment is critical, as AI touches multiple departments.
Deployment typically spans product, engineering, data, security, and compliance, meaning unclear ownership or fragmented workflows can delay releases or introduce risk. - Infrastructure decisions carry long-term financial impact (storage, compute, integration architecture).
Early choices between on-prem, cloud, or hybrid environments define not only performance but long-term run costs, retraining pipelines, and how well models scale under real user load. - Governance and compliance can’t be retrofitted once systems go live.
Without predefined access controls, auditability, and privacy safeguards, teams face costly redesigns — especially in regulated industries where model explainability and traceability are mandatory. - Scalability should be designed early, not after the proof of concept.
PoCs often perform well in isolation but fail in production without capacity planning, monitoring, versioning, and drift-prevention mechanisms built into the MLOps pipeline.
Without a roadmap guiding these decisions, organizations face the common pitfalls: expensive dead-ends, misaligned expectations, fragmented experimentation, and solutions that never reach production.
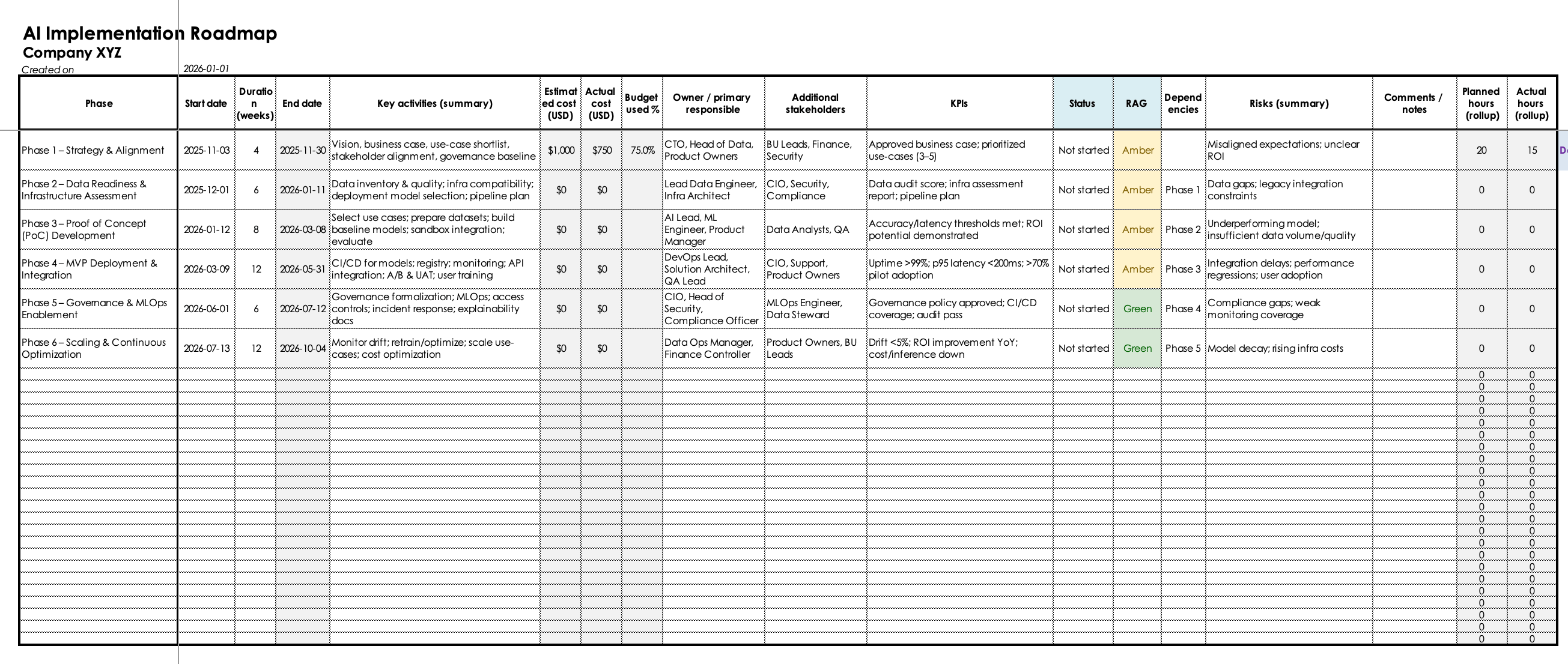
Six phases of an effective AI implementation roadmap
Implementing AI involves orchestrating data flows, integrating with existing systems, designing operational safeguards, and establishing processes for continuous improvement. The six phases of the AI implementation roadmap template outlined below break this complexity into manageable, interdependent steps that mirror real-world engineering workflows. Each phase introduces specific deliverables, technical checkpoints, and ownership roles, ensuring the project progresses from concept to production in a controlled and measurable way.
1. Strategy and alignment of the AI adoption
This stage establishes the foundation for every downstream AI decision. Before any model development or data work begins, teams need a shared understanding of why AI is being introduced, what problems it is expected to solve, and how success will be measured.
This phase typically brings together executive sponsors, product leadership, data owners, engineering leads, and compliance stakeholders. Workshops, structured interviews, and facilitated discovery sessions are the most effective formats, since they force clarity on priorities, constraints, and assumptions. Depending on organization size and the breadth of intended AI initiatives, this stage generally takes one to three weeks.
Key activities:
Define the problem spaces where AI can realistically improve efficiency, accuracy, personalization, or decision-making.
This includes mapping existing processes, identifying bottlenecks, evaluating decision workflows, and assessing where automation or predictive capabilities would materially shift outcomes.
Identify 3–5 priority use cases, considering business impact, feasibility, and data availability.
This evaluation is driven by expected ROI, operational relevance, and whether the required data is accessible, complete, and of sufficient quality for training.
Establish governance foundations: ownership, decision rights, and success criteria.
This includes defining who approves AI work, who owns outcomes, and which teams are responsible for monitoring and intervention once models are deployed.
Align stakeholders — executives, product teams, data owners, compliance.
Alignment ensures technical direction is anchored to actual business needs and regulatory obligations, reducing the risk of building solutions disconnected from organizational priorities.
Outputs:
- Validated AI use-case list
- Success metrics (KPIs)
- A shared definition of expected value and acceptable outcomes
- Time and cost expectations
A well-executed strategy phase creates clarity early, reducing the likelihood of misaligned expectations or fragmented efforts once technical work begins.
2. Data readiness and infrastructure assessment
At this stage, the focus shifts from strategic intention to evaluating whether the technical foundation can support AI workloads. This phase typically involves data engineers, solution architects, security teams, and product owners working together to assess how data is collected, stored, governed, and moved across the organization. Workshops, architecture reviews, and data audits are the most effective formats here, usually spanning several weeks depending on the complexity of the data landscape.
The goal is to understand the state of your systems before model development begins, validating whether the existing environment can support scalable training, inference, monitoring, and integration.
Key activities:
Conduct a data inventory. This includes mapping all structured, semi-structured, and unstructured data sources across the organization, identifying formats, schemas, retention policies, storage locations, and the systems or applications that generate each dataset.
Assess data quality and completeness. This set of activities involves reviewing missing values, noise levels, outliers, field inconsistencies, sampling bias, data lineage, and historical variability to understand how these issues may affect model accuracy and reliability.
Validate accessibility and integration paths. This requires confirming which datasets can be accessed securely via APIs, ETL pipelines, message queues, or batch processes, and identifying bottlenecks such as latency, access restrictions, or incomplete connectors.
Evaluate infrastructure readiness. This step of the AI roadmap creation includes analyzing compute capacity, GPU/CPU availability, storage architecture, network throughput, containerization readiness, and whether the current environment can support model training, inference, and monitoring workloads.
Check security and compliance implications. This involves reviewing encryption-at-rest and in-transit policies, identity and access management, audit logging, key management, and regulatory requirements that might impose constraints on data use for AI workloads.
Plan data preparation workflows. This requires defining how datasets will be cleaned, transformed, normalized, and enriched; selecting appropriate tools (e.g., Azure Data Factory, Databricks, Spark); and outlining orchestration steps for building repeatable, production-grade pipelines.
Outputs:
- A complete data readiness report
- Gaps and remediation actions for data quality and integration
- An infrastructure assessment outlining compute, storage, and network sufficiency
- Security and compliance requirements for the AI workload
- A preliminary data pipeline architecture for training and inference
A structured assessment at this stage ensures that model development will not be slowed down by hidden data challenges or technical constraints later in the process.
This phase directly influences model accuracy, performance stability, and the total cost of running AI in production.
3. Proof of Concept (PoC)
The PoC stage is where hypotheses about AI feasibility are tested under controlled, low-risk conditions. At this point, the strategic direction is defined and the necessary data and infrastructure groundwork has been evaluated, so the goal becomes validating whether the proposed use case can deliver measurable value. This stage typically brings together data scientists, ML engineers, product owners, and domain SMEs. The work is iterative, experimental, and requires rapid feedback loops.
PoCs are most effective when scoped tightly: limited datasets, narrowed functionality, and clearly defined evaluation criteria. Teams should aim to validate technical viability, model behaviour, and user experience expectations without over-engineering or prematurely optimizing for scale.
Key activities:
Prepare and refine datasets by extracting representative samples, defining labels, cleaning inconsistencies, and establishing ground-truth baselines for evaluation. This includes filtering noisy data, resolving schema mismatches, normalizing fields, and ensuring that training inputs reflect the operational environment the model will eventually face.
Build baseline ML models using frameworks such as PyTorch, TensorFlow, or Azure ML Designer, keeping architecture simple enough to iterate quickly.
Initial models often rely on standard architectures or pre-trained embeddings so teams can validate feasibility before committing to complex pipelines or GPU-heavy training cycles.
Experiment with feature engineering, parameter tuning, and model architectures to identify what materially improves accuracy or generalization.
This activity requires iteratively adjusting hyperparameters, testing alternative encoders, evaluating different loss functions, and logging performance metrics to determine which configurations warrant deeper investment.
Deploy the PoC model into a sandbox or isolated development environment using lightweight APIs or notebooks to validate real-world behaviour.
This controlled setup allows teams to test the model’s latency, response consistency, and compatibility with enterprise integration layers without affecting production systems.
Test outputs with domain experts to identify edge cases, fairness risks, hallucinations, or misclassifications that may impact usability or compliance.
Collaborating with product owners or SMEs ensures the PoC reflects operational realities, exposes gaps in logic or interpretability, and guides criteria for future refinement.
Outputs:
- Initial performance metrics: accuracy, recall, precision, F1 score, latency, failure cases
- Observable strengths and weaknesses in datasets
- A technical feasibility assessment for the use case
- Recommendations for MVP-level model architecture, dataset size, and infrastructure needs
- Estimated effort required to move from PoC to production-grade implementation
Many AI projects fail because teams skip PoCs or treat them as production deployments. The goal here is validation, not completeness.
4. MVP deployment and system integration
Once a proof of concept demonstrates technical feasibility, the focus shifts to releasing a controlled, production-ready version of the solution. This stage is typically led by engineering, DevOps, and product teams working together to stabilize the model, integrate it with existing applications, and ensure it performs reliably under real-world conditions. The work is usually iterative, involving short development cycles, continuous testing, and tight coordination with security and infrastructure stakeholders. Most teams conduct this phase within a structured sprint cadence or release cycle to balance speed with operational safety.
Key activities:
Build production-grade workflows and CI/CD pipelines for model deployment.
This includes automating package creation, testing, and deployment of models and inference services to ensure consistent, repeatable releases across staging and production environments.
Implement model registry and versioning discipline.
This ensures each model version is tracked with metadata, training parameters, dataset lineage, and approval status, providing the transparency required for rollback, audits, and long-term maintainability.
Integrate the AI service into existing applications and data flows.
Integration typically involves exposing models through APIs or event-driven endpoints, connecting them to front-end interfaces or backend processes, and ensuring compatibility with enterprise authentication, logging, and monitoring standards.
Set up monitoring for performance, drift, cost, and reliability.
Monitoring includes tracking latency, throughput, error rates, feature distribution, inference cost, and drift indicators, along with creating alerts that help teams detect degraded behaviour before it impacts users.
Outputs:
- Deployed MVP model
- Model registry and documented version history
- Integrated API or service endpoint
- Monitoring dashboards and alerting rules
- Test results and UAT feedback summary
A well-executed MVP phase creates a stable foundation for broader rollout by validating that the solution works reliably in real user environments and under realistic system constraints.
5. Governance and MLOps enablement
As AI systems move beyond initial deployment, organizations need a structured operating model that ensures reliability, auditability, and long-term maintainability. This stage focuses on establishing the practices, tools, and controls required to support continuous delivery, monitoring, and improvement of machine-learning systems. It typically brings together engineering leadership, security teams, DevOps, data scientists, and compliance stakeholders, working over several weeks to formalize processes and configure platform capabilities. The goal is to ensure AI systems can be safely iterated on, monitored, and governed throughout their lifecycle.
Key activities:
Define access and role management policies for AI workflows.
This includes specifying which users can modify datasets, deploy new model versions, approve configuration changes, or access inference logs, ensuring secure and auditable separation of duties across the ML pipeline.
Establish model explainability and documentation standards.
Teams define the required level of interpretability for each model type, determine documentation formats, and set expectations for feature descriptions, data lineage, training behavior, and model limitations to support internal audits and regulatory reviews.
Build automated monitoring and drift-detection workflows.
This involves configuring metrics for data drift, prediction drift, latency, error rates, and model confidence, as well as setting up alert thresholds, dashboards, and automated triggers for retraining or rollback when performance deviates.
Implement MLOps pipelines for continuous delivery.
End-to-end pipelines are built to automate model packaging, testing, versioning, deployment, and rollback, ensuring repeatability and reducing operational risk when pushing changes to staging or production environments.
Integrate compliance and data-handling controls.
Security and compliance teams define retention rules, audit log requirements, encryption policies, and GDPR-aligned data handling procedures, ensuring the AI system adheres to organizational and regulatory standards.
Outputs:
- Documented governance framework
- Access control matrix
- Monitoring and drift-detection dashboards
- Automated CI/CD and MLOps pipelines
- Compliance and audit readiness evidence
Strong governance and operational rigor at this stage ensure AI systems remain reliable and secure as they scale across new users, datasets, and business functions.
6. Scaling and continuous optimization of AI adoption process
After an initial AI solution is deployed successfully, the focus shifts to sustaining performance, expanding capabilities, and ensuring long-term ROI. This stage involves ongoing collaboration between technical teams, operational stakeholders, and product owners to refine models, extend AI adoption across new workflows, and maintain stability as real-world data patterns evolve. Work at this stage is typically continuous rather than time-boxed, with periodic review cycles and structured maintenance windows to ensure that production systems remain reliable and relevant.
Key activities:
Monitor model performance, drift, and operational behavior in production.
This includes tracking prediction accuracy, latency, error rates, and monitoring data distributions to detect drift or degradation that may require retraining or architecture adjustments.
Refine and retrain models using new, more representative datasets.
Teams incorporate fresh data from user interactions, business processes, or sensor inputs and ensure updated models are validated, versioned, and deployed with rollback options.
Extend AI capabilities into adjacent business areas.
Expansion decisions are guided by value potential, reuse of existing pipelines, and technical feasibility, often involving replication of proven components, inference endpoints, or data pipelines into new domains.
Continuously optimize infrastructure and cost.
This involves tuning compute resource allocation, storage tiers, model compression or quantization, and adjusting batch vs real-time processing strategies to reduce cost while maintaining performance.
Formalize long-term ownership and operational playbooks.
Teams define escalation paths, intervention rules, and documentation standards to ensure AI systems remain maintainable as organizational structures evolve.
Outputs:
- Updated and retrained models
- Expanded use-case portfolio
- Cost-optimized infrastructure configuration
- Performance reports and drift analysis
- Long-term operational guidelines
Sustained optimization in this phase ensures that early wins compound over time and that AI systems remain adaptable as business conditions, data patterns, and operational requirements evolve.
.png)
Common pitfalls and how to avoid them during the AI implementation roadmap creation
AI initiatives tend to encounter similar failure points, not because the technology is inherently fragile, but because teams underestimate the interaction between data, infrastructure, governance, and downstream system dependencies.
Addressing these risks early shapes whether AI becomes a measurable operational asset or an expensive experiment that never graduates beyond the prototype stage.
1. Lack of clear problem definition
Teams often begin with an algorithm-first mindset, exploring models without anchoring them to operational bottlenecks or measurable targets. This leads to outputs that don’t translate into business value or fit naturally into existing workflows.
Fix: Tie every use case to quantifiable KPIs, define what “improvement” means, and validate with process owners that the outcome will influence a real decision or action.
2. Overestimating data quality and availability
Datasets frequently contain gaps, inconsistent labels, sampling bias, or incomplete lineage, issues that only surface once modelling has already begun. These deficiencies degrade accuracy, introduce drift, or make models unsuitable for production.
Fix: Perform structured data-readiness assessments, including profiling, schema auditing, lineage checks, and access validation before development begins.
3. Underestimating integration complexity
Even well-performing models fail when integration paths are brittle or undefined. Productionising AI requires pipelines, stable APIs, event triggers, error-handling logic, model registries, and monitoring hooks.
Fix: Treat integration as part of the build process by designing deployment workflows, API specifications, governance endpoints, and observability early in the lifecycle.
4. Insufficient MLOps capabilities
Without automated monitoring, retraining, and versioning, models degrade silently as underlying data changes. This results in performance regressions, reliability issues, or compliance gaps that remain undetected until users escalate failures.
Fix: Implement automated drift detection, logging, performance alerts, reproducible training pipelines, and model registry controls, ensuring traceability across the entire lifecycle.
5. Weak governance and compliance foundations
AI systems that lack explainability, access control, and auditability become difficult to certify and deploy, especially in regulated environments. Retrofitting compliance later is costly and often infeasible.
Fix: Define governance requirements early and connect them to infrastructure-level safeguards, including identity and access management (IAM), encryption policies, bias testing, audit logs, and documentation standards.
6. Skill gaps across engineering and data functions
Many teams lack the specialised expertise needed to design architectures, validate pipelines, ensure data reliability, or manage production-grade AI systems. These gaps impede progress and increase technical debt.
Fix: Bring in AI-focused consultants or external engineering support to assist with architecture design, pipeline hardening, model validation, scalability planning, and risk modelling, enabling internal teams to build on a more solid foundation.
How to use the AI Implementation Roadmap Template
This template provides a structured, practical way to plan and document all stages of your AI adoption effort. It is intentionally designed in a modular way, allowing teams to use either the high-level phase view, the detailed activities view, or the combined view, depending on the size of the initiative and preferred project-tracking style.
1. Start with the Roadmap tab
Use this sheet to outline the major stages of your AI implementation.
Populate the key fields:
- Phase name – e.g., Strategy & Alignment, Data Readiness, PoC, etc.
- Description / objectives – 1–2 sentences summarizing the purpose of the phase.
- Start and end dates – planned timeline for the stage.
- Owner – the person responsible for overseeing this phase.
- Status – select from the drop-down to track progress.
- Notes / assumptions – space for context or decisions made.
This view is ideal for leadership alignment, stakeholder communication, and long-horizon planning.
2. Add detailed work in the Activities tab
Each activity represents a specific task, deliverable, or work package inside a phase.
Fill in:
- Phase – select which stage the activity belongs to.
- Activity name – clear, actionable description.
- Owner – responsible individual or team.
- Planned start / end dates – expected timing.
- Effort (hours) – useful for rough workload sizing.
- Status – Not started / In progress / Completed.
- Dependencies – predecessor tasks or cross-team requirements.
- Notes – additional detail, risks, technical constraints.
This view is best suited for coordinators, project managers, and technical leads who need operational clarity.

3. Use the Combined Roadmap with Activities tab when you need both
The combined sheet merges phase-level structure with line-by-line activities, allowing teams to view the roadmap holistically.
You can:
- Review phases alongside their associated tasks
- Track workload and progress in one place
- See how activities roll up into each stage
- Identify bottlenecks or misaligned timelines quickly
Teams running multi-month or multi-team AI initiatives will find this layout the most convenient.

4. Tailor the template to your workflow
You can use only one tab, all tabs, or a combination. Smaller teams might rely solely on the Roadmap, while larger or cross-functional teams may prefer the Roadmap with Activities and Activities sheets for more granular planning. Download your AI integration roadmap template there.
When expert support is recommended in AI adoption strategy process
While the roadmap provides a structured foundation, certain scenarios require specialized expertise, especially when architectural decisions, compliance obligations, or production-grade operations are involved. These areas typically demand skills and experience that extend beyond general software development or analytics capabilities.
Advanced MLOps and lifecycle management
Building the PoC is only the midpoint of the journey; sustaining a production model requires automated pipelines, reproducible training processes, audit-ready versioning, and continuous monitoring. Expert support helps design CI/CD workflows, implement drift detection, configure real-time telemetry, establish rollback mechanisms, and handle model registration, lineage, and artifact governance. Without these elements, models degrade silently and introduce operational risk.
Custom infrastructure design
AI workloads place unique demands on compute, networking, storage, and orchestration. Consultants can design infrastructure that balances latency, scalability, and cost, for example, deciding between GPU clusters, serverless inferencing, hybrid deployments, or container-based architectures. They ensure that data movement, model execution, and dependency graph complexity do not exceed what the existing system can reliably handle.
Compliance-heavy environments
Industries such as healthcare, finance, government, and insurance require strict controls on data handling, model explainability, audit trails, identity management, and bias detection. AI specialists translate regulatory frameworks (GDPR, HIPAA, PCI-DSS, ISO 27001) into technical safeguards such as encryption standards, role-based access policies, interpretability frameworks, and event logging pipelines. This reduces the risk of non-compliance and accelerates approval cycles.
Enterprise-level system integration
Connecting AI models to enterprise ecosystems involves more than exposing an endpoint. It requires stable data pipelines, message brokers, workflow orchestration, retry logic, schema versioning, and consistent error-handling patterns. Experts ensure that AI components sync reliably with CRMs, ERPs, data lakes, warehouse systems, WMS, and core transactional platforms — without introducing downtime or breaking existing business processes.
Skill-gap support for teams new to AI
Many organizations have strong engineering or domain expertise but lack deep experience with modern machine learning workflows. External specialists can accelerate early decisions, validate architectural assumptions, mentor internal teams, and ensure that implementation follows patterns proven to work in real production environments. This avoids inefficient trial-and-error cycles and ensures the roadmap is executed with confidence, technical accuracy, and long-term sustainability.
Organizations without internal AI talent or with limited exposure to modern ML workflows often gain significant efficiency, quality, and cost benefits by engaging specialized consultants at key moments in the journey.
Conclusion: Start your AI adoption journey with structure, clarity, and confidence
Artificial Inteligence delivers value when implemented with intention, discipline, and cross-functional coordination. A structured roadmap helps teams move from experimentation to production with fewer risks, clearer responsibilities, and measurable business outcomes.
To support your journey, we’ve created a free, comprehensive AI Implementation Roadmap Template, to be used by teams preparing to adopt AI in real-world software and data environments.









